 SPIP Blog
SPIP Blog La mécanique des statistiques
La mécanique des statistiquesEn mars dernier, avec le Spam de l’Empaqueteur, nous tentions d’apporter réponses à certaines interrogations quant au fonctionnement un peu magique du service web le plus important pour la communauté, celui de la mise en paquet du système de publication et de ses plugins.
Aujourd’hui, après 2 billets exploitant les données du site https://stats.spip.net, nous allons chercher à en expliquer la mécanique aussi. Toujours en mars dernier, François-Daniel met les pieds dans le plat, merci à lui. Bruno apporte un premier lot de réponses, merci aussi à lui. Voici donc un complément.
Polysémie
D’une manière générale, il faut avoir en tête que pour pour faire des mesures statistiques avec « SPIP » comme mot-clé sur des services web communs à l’humanité toute entière, c’est compliqué à cause de sa polysémie. Notre CMS n’est pas un écureuil de bande dessinée, ni un outil d’analyse d’images, ni un service de l’administration pénitentiaire française. Un soucis que ne connaissent pas wordpress, drupal, joomla et les autres. Les 30 Millions de résultats de SPIP sur google ne concernent pas le CMS uniquement, alors que les 95 Millions de résultats de drupal ne concernent que lui.
L’Outil en lui-même
Au tout début, il y a 12 ans, à partir de février 2007 et pendant 3 ans, top10 est une initiative visant à produire des statistiques à partir de l’article/pétition Des sites sous SPIP. De script shell à plugin SPIP et intégrant une analyse des liens entrants (les referers) du site où il est installé et activé, le mécanisme sera généralisé sous le nom d’univers_spip en 2010. L’« exploration du web » commence véritablement à ce moment-là puisque le plugin va scanner désormais l’api twitter, l’api yahoo boss, le service google news, ainsi que des réseaux sociaux tels del.icio.us (pour le référencement des sites sous sarkaspip) et identi.ca.
Ce qu’on trouve derrière le site aux rectangles bleus, c’est donc un plugin SPIP embarquant son lot de PHP, ses squelettes SPIP et ses boucles, un peu de CSS et du (vieux) Javascript ainsi qu’une (aussi vieille) implémentation d’une librairie de géolocalisation par adresse ip (pour avoir une idée de la provenance géographique des sites).
Il est développé sur la zone, mais pas dans le répertoire traditionnel des plugins et il n’est pas mis en paquet par l’empaqueteur, de par sa fonction un peu particulière. Aucune page ne lui est donc dédiée sur plugins.spip.net. Il n’est pas documenté non plus. La mise à jour du plugin sur contrib.spip.net est à la charge de l’hébergeur du site.
Progressivement, les services scannés disparaissent et il ne reste aujourd’hui que la pétition des Sites sous SPIP, les referers du site contrib.spip.net et la recherche twitter via un flux de syndication au format RSS auto-hébergé sur le présent blog.
Enfin, on peut dire qu’il n’évolue plus beaucoup depuis quelques années mais qu’il marche quasiment tout seul, un peu comme l’empaqueteur.
Aujourd’hui, Il effectue 4 tâches.
Exploration du web
2 sources sont alternativement scannées, toutes les 4 minutes.
- Un flux RSS des Sites sous SPIP du site officiel
- Un flux RSS hébergé par ce blog fournissant les résultats de la recherche du terme « spip.php » sur Twitter.
Le résultat de ces explorations, une liste d’adresses de sites potentiels, est "proposé" en étant inséré dans une table de la base de données.
Ainsi, toutes les 8 minutes, la base est "mise à jour" en ayant fait le "tour du web".
Traitement des referers
Toutes les 12 heures, les liens entrants de la veille et qui ressemblent à une adresse de site SPIP sont "proposés" comme s’ils étaient le résultats d’une exploration du web.
Vérification
Toutes les 97 secondes, 3 analyses différentes sont effectuées sur les sites potentiels repérés par l’exploration du web, ainsi qu’une mise à la poubelle (ce qui n’est pas pareil que de "refuser" un site) des sites que l’on considère comme morts ou dont le nom de domaine n’existe pas (ou plus).
- analyse de 2 sites proposés,
- analyse de 5 sites connus pour une nouvelle vérification,
- analyse d’un site connu qui n’a pas répondu correctement au dernier passage.
Pour analyser un site, on va tester son adresse en s’assurant qu’on récupère bien un contenu et quelques informations (des entêtes HTTP) en faisant croire qu’on vient de google.fr [1]. Les entêtes permettent de déterminer la version de SPIP, la version de PHP ainsi que la liste des plugins activés et leur version.
Le fait de récupérer un contenu fait passer le statut du site potentiel à « publié ». on lui associe ce que les entêtes ont bien voulu donner.
Il est à noter que l’hébergeur peut choisir de masquer la version de PHP utilisée (pour des raisons de sécurité) et les webmestres des sites SPIP peuvent en faire quasiment autant avec SPIP et ses plugins ($spip_header_silencieux) voire traficoter selon son bon plaisir la constante _HEADER_COMPOSED_BY ...
Traitement d’historisation
Tous les 3 jours, un fichier JSON est généré avec le nombre de sites pour certaines versions de SPIP. Nul ne sait ce que devient ce fichier de nos jours ...
Conclusion
Dans une certaine mesure, on peut admettre que tout ceci est un travail original mais qu’il n’est guère maintenu activement depuis quelques années. L’intérêt de son adaptation à d’autres CMS est quasi nul., au regard de ce que produisent certaines sociétés telles que w3techs, et sachant que chaque CMS fournit ses propres statistiques sur des pages générées par leur propre outil.
Les conséquences :
- Pas de comptage des téléchargements, pas de statistiques d’utilisation de spip_loader, pas d’info sur les passage de version de SPIP (voire de PHP si on le souhaitait), on ne compte que la présence d’une page d’accueil,
- pas d’info sur les sites intranet ou extranet (nécessitant un login pour le site "public"), puisque les sites potentiels sont vérifiés par le site contrib.spip.net et qu’il ne peut atteindre que des sites publics,
- pas de site utilisant des URLs propres ou personnalisées, on a besoin du terme "spip.php" pour identifier un site potentiel,
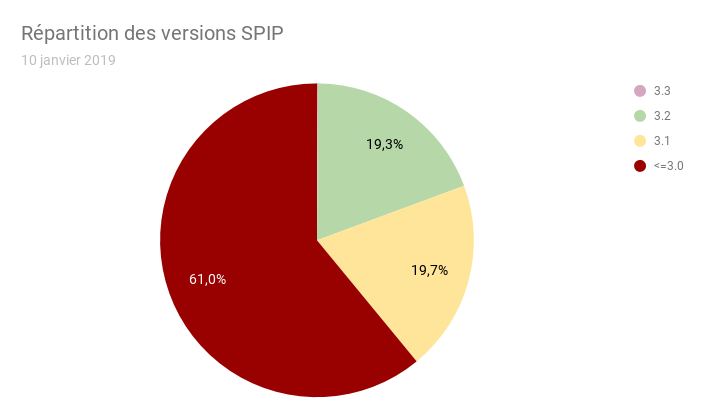
- pas d’infos sur les sites qui masquent leur version de SPIP.
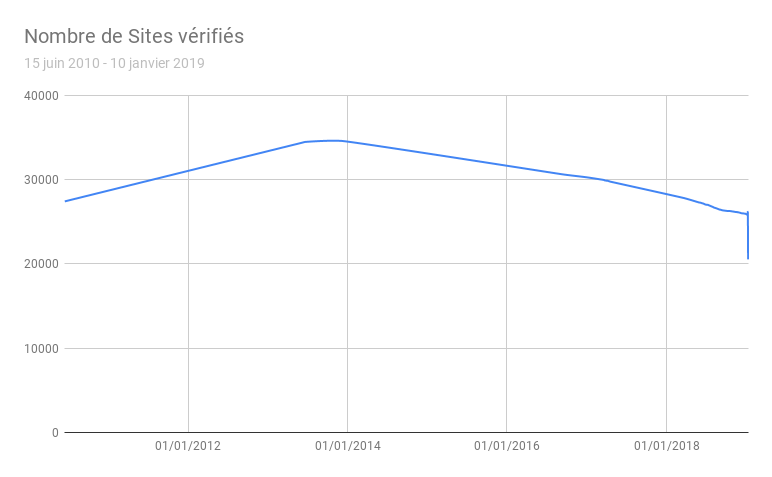
Si on souhaite que le nombre de sites vérifiés augmente :
- Pensez à référencer les sites que vous créez sur la pétition « Des Sites sous SPIP ».
- Utilisez de préférences des urls de types « pages » ou « simples »,
- Faites des liens vers des articles du site contrib.spip.net depuis ces sites, arrangez-vous pour que quelqu’un clique et enfin,
- Parlez des vos créations sur twitter avec les liens contenant le terme « spip.php ».




Messages
5 décembre 2018, 08:40, par _Eric_
Juste un rappel concernant ces statistiques :
SVP Statistiques le plugin addon de SVP utilise la page http://stats.spip.org/spip.php?page=stats.json pour récupérer les stats d’utilisation de chaque plugin qui sont affichées dans Plugins SPIP. J’avais aussi prévu d’historiser ces stats pour présenter la courbe d’utilisation de chaque plugin mais je ne l’ai jamais fait.
Aujourd’hui les statistiques d’utilisation des plugins de Plugins SPIP concernent l’ensemble des versions de SPIP. La page d’accueil aussi met en vedette les plugins les plus utilisés pour l’ensemble des versions de SPIP. Il serait peut-être judicieux de se focaliser sur les statistiques de la version stable courante pour être plus en phase avec l’utilisation actuelle (par exemple, CFG n’est plus utilisé alors qu’il apparait toujours en tête des plugins).
5 décembre 2018, 11:26, par jeanmarie
Salut !
merci de décortiquer tout ça, ça permet de mieux comprendre le fonctionnement.
2 remarques :
– est-ce que les referer de www.spip.net sont aussi pris en compte ? C’est le principal lien mis en place sur les sites, sans doute plus que contrib.
– pour les types d’URL, il est plutôt conseillé d’utiliser des adresses qui ont du sens pour le visiteur (donc URL propres). Pas sûr que conseiller « page » ou « simple » pour des raisons techniques de stats (en tout cas sans précision) soient la bonne idée :)
Au niveau des sources, les referers du site contrib.spip.net sont-ils ceux qui mettent à our leur plugins depuis SVP ?
Et il y a aussi l’info de version qui se trouve en bas de chaque page du privé. Cette info doit générer des hits traçables qui seraient efficaces, non ?
jean marie
5 décembre 2018, 12:34, par James
J’ignorais que les statistiques des plugins étaient exploitées quelque part, parce que les données remontées sont complètement incohérentes (ex : pour 26085 sites vérifiés à l’instant t, cfg est annoncé présent sur 34256 sites, soit 135.4% des sites).
Les seuls liens entrants (referers) pris en compte sont ceux du site où le plugin est activé, à savoir contrib.spip.net. Donc, non, les referers de spip.net ne sont pas exploités.
Pour le SEO, je me doute, bien évidement, que les URLs propres, c’est mieux. Ce que j’ai écrit est une manière d’alerter sur le sujet, justement :-). Merci d’avoir relever la contradiction ;-)
Je ne vois pas le rapport entre les referers du site contrib.spip.net et SVP. Peux-tu préciser ta pensée ?
Sauf erreur, la version qui se trouve en bas de chaque page du privé n’est pas un lien vers quoique ce soit. Mais il est vrai qu’il y a un mécanisme qui permet de savoir s’il y a une nouvelle version de SPIP. Ce mécanisme pourrait peut-être être exploité, en effet... Plus généralement, à ma connaissance, aucun log apache (ou de tout autre type de serveur web) n’est utilisé pour faire des stats publiées quelque part, a fortiori sur le sites des stats, d’où ma remarque sur le fait qu’il n’y a pas d’info sur les téléchargements de paquets et l’usage de spip_loader. Traiter les stats du site https://files.spip.net serait sans doute intéressant.
5 décembre 2018, 15:51, par Loiseau2nuit
Euh... idée toute bête mais, afin d’avoir des stats plus fiables et surtout, de by-passer les petits malins dans mon genre qui bloquent la connection des scipts se faisant passer pour Googlebot (fail2ban jail dédiées anti « fake search bots » + mise au ban manuelle d’IP reconnues comme telles en analysant mes logs).
En l’état je ne suis même pas certain que stats.spip soit capable de retrouver un seul de mes sites ! En fait je suis même plutôt certain du contraire, alors que :
Parce qu’avec ça, même des sites comme les miens remonteraient dans les stats (à moins de bloquer l’indexation google) et la pertinence des résultats serait à mon avis beaucoup plus proche de la réalité, qu’on ne l’est aujourd’hui en multipliant les requêtes hasardeuses sur des sources éphémères, qui plus est bien moins renseignées que Big G d’une manière générale. Non ?
5 décembre 2018, 15:54, par Loiseau2nuit
>> James :
Est-ce ca, ça ne viendrait pas d’une « mauvaise » désinstall (c.a.d désactivation simple et suppression manuelle du plugin sans passer par l’option idoine « Désinstaller ») ce qui du coup conserverait des infos metas ou autres quelque part dans le système, générant du faux-positif ???
6 décembre 2018, 11:18, par James
D’abord, une précision, j’ai oublié de corriger une erreur dans le billet avant sa publication à propos de la collecte quant à l’utilisation de google.fr. Techniquement, on en fait un referer, pas un User-Agent. Quoiqu’il en soit, l’appel à
ecrire/est testé dans certains cas. Et pour les sites SPIP qui cachent leur version, je pense que c’est le cas pour entre 1% et 3% des sites vérifiés... Il convient bien sûr de respecter le choix de celles et ceux qui ne souhaitent pas divulguer des informations techniques.Ensuite, ne vous mettez pas en tête et ne commencez pas à propager l’idée que les stats ne sont pas fiables. La collecte est ce qu’elle est, mais la volumétrie traitée peut être considérée comme un échantillon représentatif. Comme je l’expliquai sur la liste de discussion des utilisateurs, ce qui est important c’est d’observer des tendances.
Donc, les stats sont fiables. Je ne fais des mesures que sur les versions SPIP et PHP, pas sur les plugins.
Si vous voulez améliorer la collecte avec des méthodes plus « complètes » et aider à corriger le défaut sur les plugins, je vous invite à vous rapprocher des développeurs/mainteneurs historiques sur la liste spip-zone@rezo.net ;-)
Je vous encourage surtout à participer à la réflexion sur un moyen de renverser les tendances observées. :-)
24 décembre 2018, 11:37, par James
Juste pour préciser ici : L’URL à privilégier est https://stats.spip.net (cf. https://zone.spip.net/trac/spip-zone/changeset/113096/spip-zone). ça réduit le nombre de requêtes HTTP et c’est bon pour notre empreinte écologique. ;-)
J’ai corrigé les boucles d’affichage des plugins (merci Marcimat) et c’est en ligne maintenant. ça affiche des données cohérentes (porte_plume passe de 210% d’usage à 77% et cfg passe de 135% à 33%)
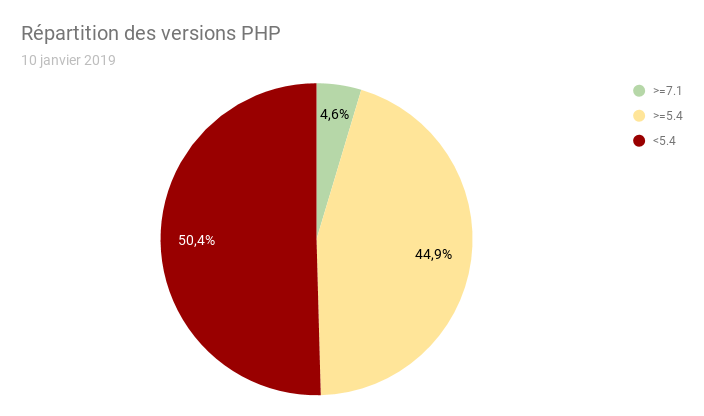
J’ai ajouté une branche PHP qui était manquante (4.4), et ça change considérablement la représentation de PHP puisque cette branche représente 13% de la base installée alors que c’est une branche abandonnée depuis plus de 10 ans.